


- 2,177Commits 数量
- 6,097Star 数量
- 132Contributor 数量
- 270Watch 数量
- 1,179Fork 数量
- 1,682PR 数量
项目简介:
PikiwiDB(原名Pika) 是一个用于存储数据的数据库,它是一种高吞吐、低延时、可持久化的分布式大容量类 Redis 存储服务,它完全兼容了 Redis 协议,拥有性能优越以及存储成本低的有点,解决了Redis内存容量大小限制以及存储成本高的问题。
项目特点:
技术价值: PikiwiDB 是一种可高吞吐、低延时、可持久化的分布式大容量类 Redis 存储数据库,它完全兼容 Redis 协议,比如常用数据结构 bitmap、string、hash、list、set、zset、geo、hyperloglog 等,用户无需做代码修改, 即可把服务从 Redis 迁移到 PikiwiDB 服务。PikiwiDB 底层采用了 RocksDB 作为存储引擎,支持数据存储化存储,提供了毫秒级别的延时性能,提供了 TB 级别的存储能力,解决了 Redis 内存容量大小限制以及高成本的问题。此外,PikiwiDB还支持主从复制、分布式、水平拓展集群和故障自愈能力,以满足分布式业务场景下用户的需求。目前,PikiwiDB 也积极在 Serverless 领域进行探索,以给用户带来更流畅的使用体验!
业务价值: 如今,PikiwiDB 正在开发 Serverless 架构的相关功能,Serverless 架构是目前业界最新发展趋势,它可以将应用程序的开发周期缩到最短,因为它可以实现自动管理应用程序的部署和运行,从而减少了开发人员需要管理的基础架构和服务器的数量。同时,Serverless 架构可以根据应用程序的需求动态地分配和释放资源,从而实现更高的可伸缩性,使应用程序可以在高峰期自动扩展,在低峰期自动缩减资源,从而提高资源利用率,并保障了服务在任何时刻的高可用性。这个功能也正是目前市场上已开源产品所缺失的功能,这也将成为 PikiwiDB 的核心竞争优势。
国内外开源的 KV 数据库,比如 Redis、RiakKV、Tigris、Todis 等,都在 Serverless 领域进行了探索,比如存算分离、云化存储、弹性伸缩、故障自愈等。但是,业界在这些功能的实现上都还有不少的缺陷,比如,如何在云化存储时保证程序的性能、如何实现用户无感知的弹性伸缩、如何实现稳定的自动运维等问题。在高性能、低成本、易用性、用户范围和社区活跃度等方面,PikiwiDB 也一直走在业界前列;在开源社区,以及国内互联网公司也得到了大家很多的认可。
我们拿业界使用最广泛的 Redis 和 PikiwiDB 做压测比较,在同样的硬件条件下;SET 命令 PikiwiDB 的吞吐量能达到 22 万,Redis 的吞吐量为 18 万,GET 命令 PikiwiDB 的吞吐量可以达到 50 万 QPS,Redis 的吞吐量为 19 万;其他的大部分命令,PikiwiDB 的吞吐量都要比 Redis 更优秀。详情可以参考文档:https://deep011.github.io/pika_benchmark 。
生态价值: 由于 PikiwiDB 项目优秀的性能以及低成本优势,使得 PikiwiDB 在行业内受到广泛的欢迎,在一些大公司内部都有在线上环境部署和使用 PikiwiDB。例如,PikiwiDB 在 360 内部部署实例 10000+,覆盖了公司内部搜索、浏览器、游戏等多个大流量的业务场景,给各个业务线提供了高吞吐(30W QPS)、低延时(2ms 延时)以及低成本(数据持久化到磁盘)的 KV 服务,每年为公司带来 1.2 亿元的成本收缩;喜马拉雅公司基于 PikiwiDB 进行改进并开源了 XCache 服务,截止目前 XCache 在喜马拉雅公司内部署实例数量 6000+,数据量 120TB+;微博公司内部部署 PikiwiDB 实例 10000+,日承接数据千亿级别,保障了新浪内部高流量的业务的稳定性;个推公司内部基于 Codis 搭建了 PikiwiDB 集群,目前部署了 300+ PikiwiDB 实例,总数据量达到了 30TB+;除此之外,美团、小米、迅雷、脉脉、58 同城、唯品会、亿玛等公司,也在公司内部使用了 PikiwiDB 服务,满足业务的同时降低使用成本。
项目架构:
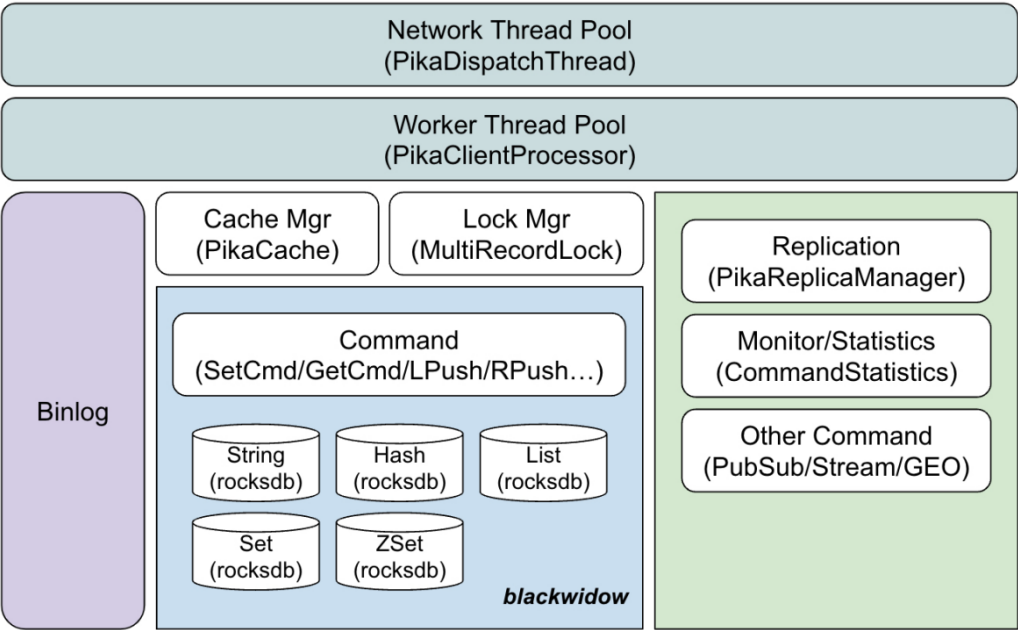
单机架构:
 集群架构:
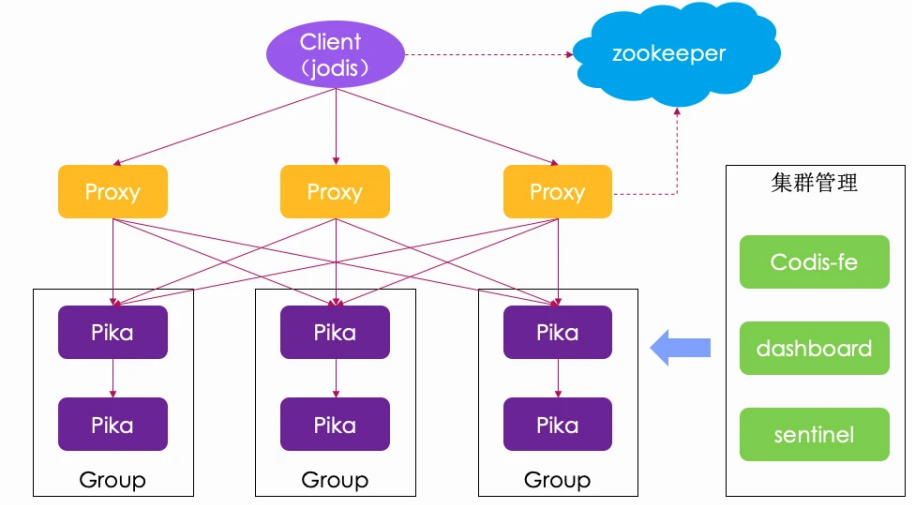
集群架构:
'/%3e%3c/g%3e%3c/svg%3e)